This blog is in four key parts:
- The background of this investigation including links to the diagnosis, data and existing information on the limitations of NVivo with Right-to-Left scripts.
- A detailed explanation and illustration of how Arabic and other right to left scripts are rendered in NVivo.
- Proposed workarounds and alternative software products including their benefits and potential limitations.
- Next steps and updates
Background
I recently has the amazing opportunity to work with the Palestinian Central Bureau of Statistics in Ramallah to provide technical consultancy and capacity building in qualitative research methods. This was through working with CLODE Consultants, a UAE-based business specialising in statistics, and the use and management of data. CLODE consultants operates in both Arabic and English, providing worldwide training, research, and consultancy services. I am working as a consultant with CLODE Consulting to provide expertise on qualitative and mixed-methods in order to meet the growing needs of customers for those approaches in this data driven age.
The PCBS approached us to provide technical consultancy in using NVivo as the market-leading product. They had engaged with the built-in projects and excellent YouTube videos and identified it as having the features required for their needs to increase an engagement with qualitative and mixed-methods approaches to inform and enhance statistical analyses.
However, through working to develop materials and workshops I rapidly encountered hard limits with working with NVivo and Arabic text, combined with a relative lack of clear documentation or explanation of the limits or workarounds.
NVivo may not operate as expected when attempting to use right to left languages such as Arabic. We recommend you download and work with your data in our NVivo free trial Software first.
Searching online on forums identified some cursory information interspersed with promotional puff on ResearchGate, a proposed workaround to use images or region coding on PDFs on the NVivo forums, pleas for improvements in this area dating back to 2010 on the NVivo feature request forum and the most comprehensive response in the QDA Training forum by Ben Meehan
So I was left to do some experimentation myself and then to work with staff at PCBS who could read arabic to explore and consider what the limits are and how they affect research.
Example data:
Whilst I would normally steer WELL away form such a politically sensitive topic or text in this case as example data I am drawing on the interview in June 2018 between Jared Kushner and Walid Abu-Zalaf, Editor of the Al Quds newspaper. I STRONGLY emphasise this is NOT because of the subject matter nor in any way agreement with, support of or condonation of the the content (in fact I find the person pictured and politics he represents really repulsive) however it was selected purely for practical purposes: it is freely available and includes a full English translation. The text – both Arabic and English is available from http://www.alquds.com/articles/1529795861841079700/
The text was copied and pasted into a word document and formatted as “traditional arabic font) with minimal clearing up of opening links etc.
Arabic text Word file available here.
Additionally the page was printed as a PDF – available here and converted to a PDF via https://webpagetopdf.com/ as well – resulting PDF available here.
Finally it was captured as both article as PDF and page as PDF via NCapture creating 2 .nvcx files (linked).
Computer System Setup:
I added Arabic (Jordan) as a language pack following information from Microsoft about adding languages. (Previously without the language pack installed the computer rendered Arabic script in western fonts (e.g. times new roman) which slightly reduces legibility and affects rendering.)
Working with NVivo and Arabic Script
NVivo works strictly left-to-right. This has serious implications when importing Arabic, Hebrew, Urdu, Persian or other Right-to-Left scripts as data.
If we look at the word document in word – the text copied from web and pasted into word file it appears like this:
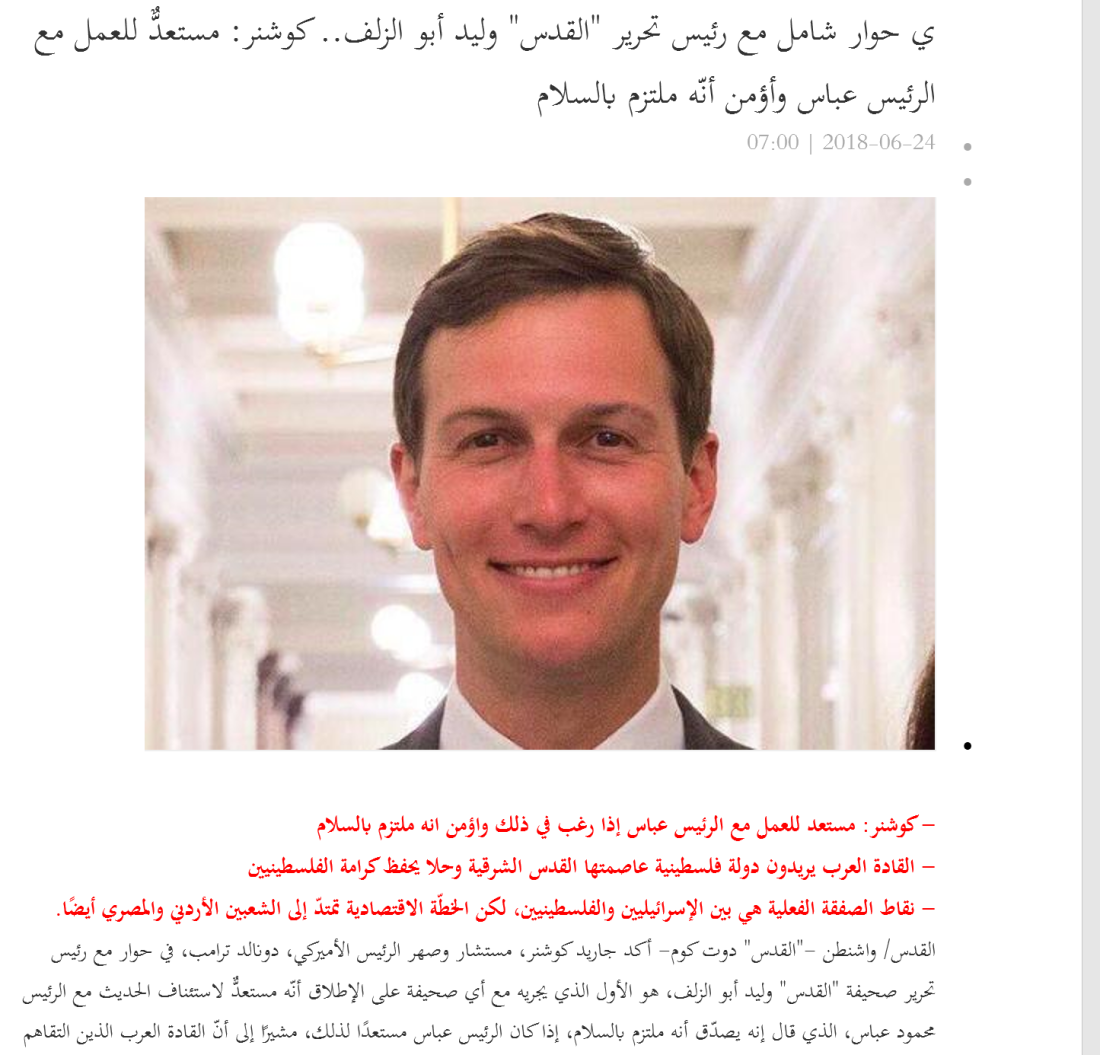
When imported into NVivo substantial changes are made through the import process:
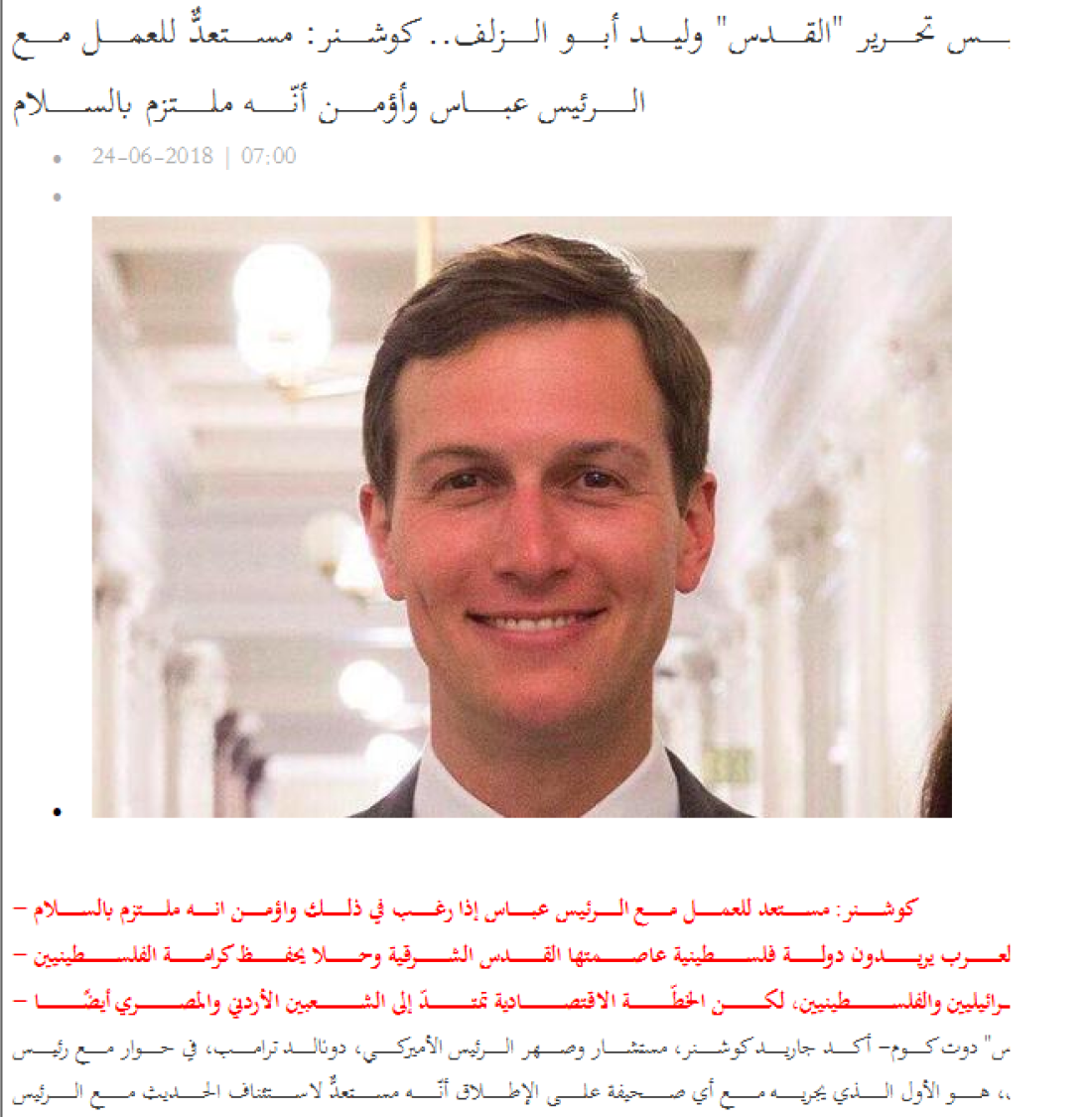
A number of serious issues follow. Firstly the text is now VERY hard to read. Secondly while you can edit the document t make the text right aligned so it appears better, the reading and selecting direction remain unaffected.
Thirdly, and most seriously – you cannot select therefore cannot search for, code or annotate, the start of paragraphs:

The workaround would then seem to be PDFs – while accepting limitations with those in NVivo, e.g. you cannot auto-code for speaker or using document structure.
However the selection issues remain especially when importing web pages as PDFs via NCapture produces similarly odd results, apparently OK until you try to select content:
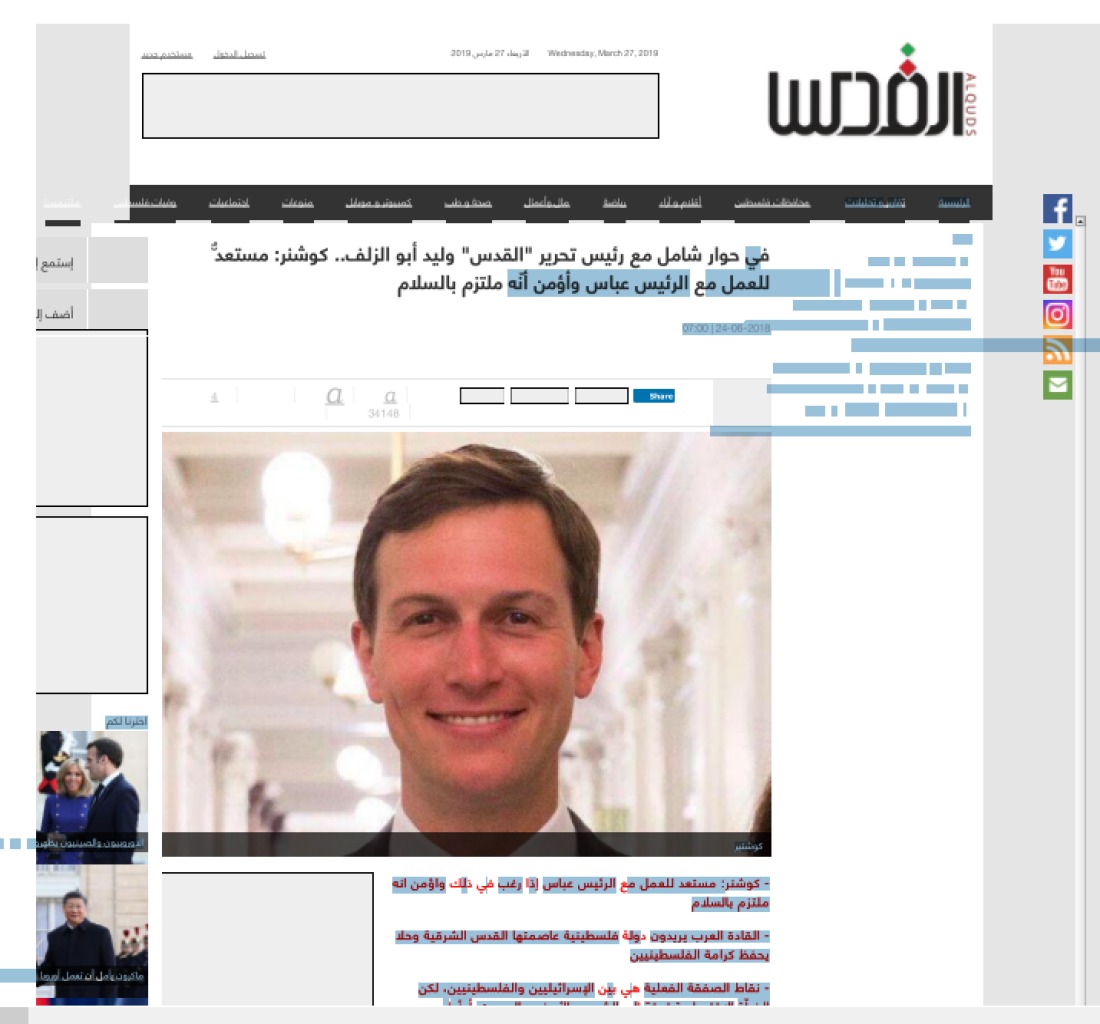
As you can see selecting (and therefore coding text) is all over the place.
Article as PDF fares best, however selection still runs left-to-right:

The print as PDF and convert to PDF versions also had substantial issues with text selection – showing it isn’t just NVivo and NCapture that struggle here.
Effects on queries
There are then a series of oddities that result. Copying and pasting the text بأنهم ي and running a text search does work but gives odd results when there should be four identical copies of the same text:
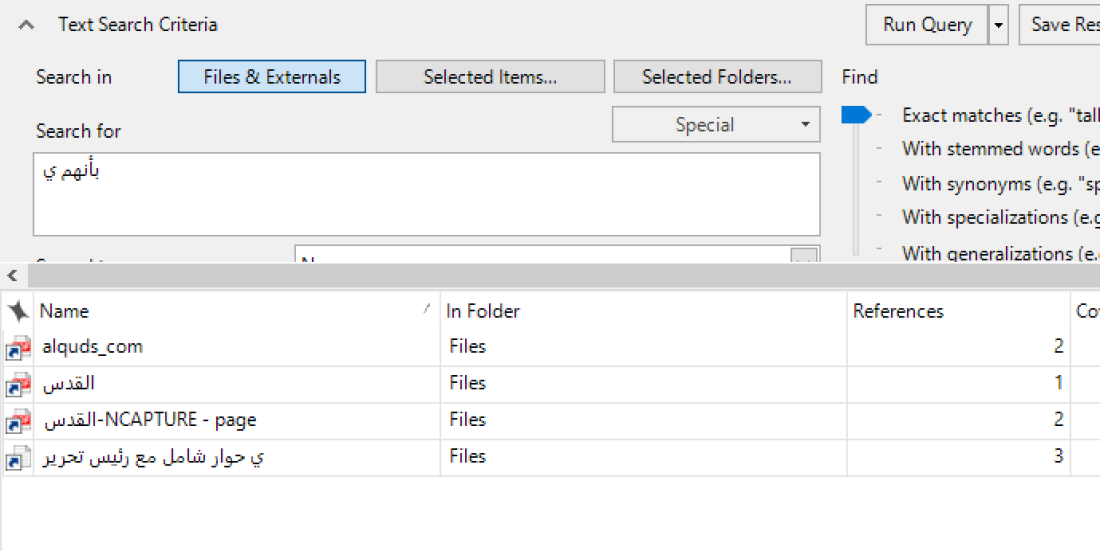
Furthermore when you look into the results they seem not to be the actual text searched for:
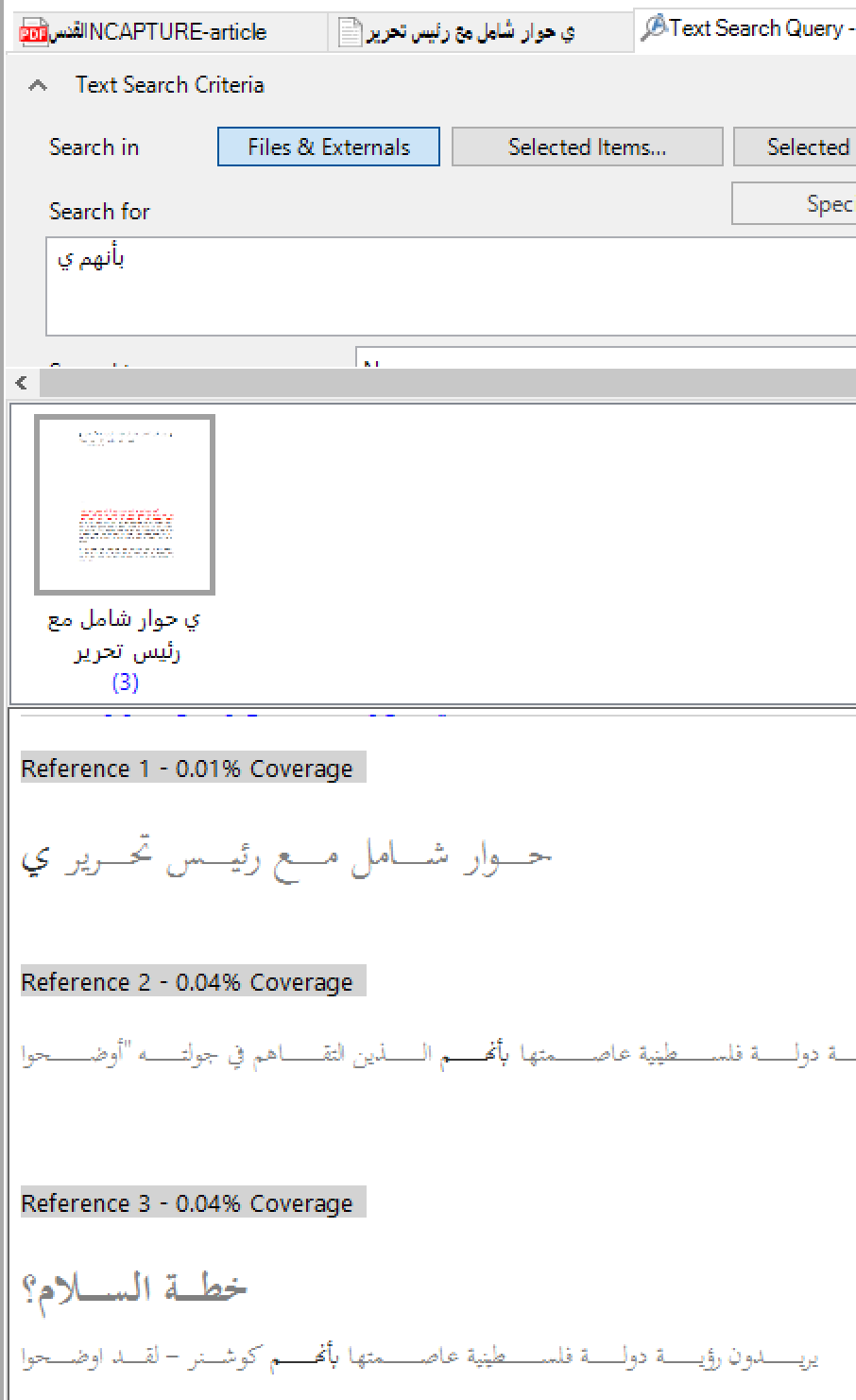
At this point I must point out that I do not speak nor read Arabic so what remains is what I have been told about query results.
Word frequencies appear to work. As this was bi-lingual I had to spend a VERY frustrating period of time trying to select just the Arabic text in the PDFs without selecting English as well and then coding it with a node for “Script-arabic” to scope the word frequency query to that node. Here are the results – pretty, but I also think pretty useless:

You can then double-click a word in the cloud and view a text search – however the results are as problematic in legibility as those identified above.
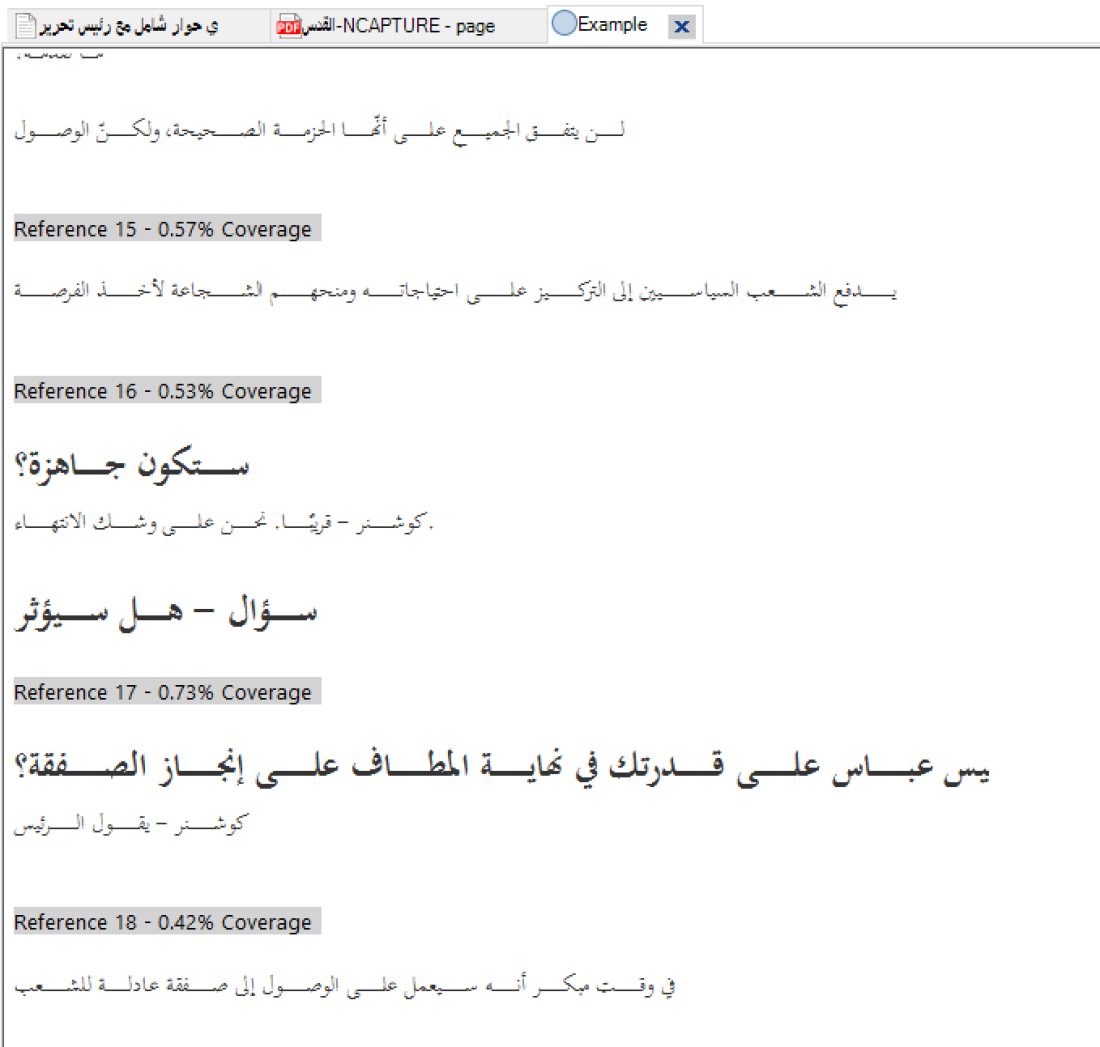
ًIf you do select and code Arabic text then when you run a coding query and look at the results the staff I worked with at PCBS told me that the results were illegible “like looking at text in a mirror”:
What to do?
The limits are pretty serious as I’ve set out. It is more than just fiddly selection but runs through to text being at all legible / readable or usable.
Recommendations for approaches in NVivo and alternative packages:
If you MUST use NVivo:
Then use PDFs and use region selection i.e. treat arabic text as an image and accept the limitations.
If you can choose another package
All (yes ALL!) the other leading CAQDAS packages support Arabic and other right-to-left scripts. So it then comes down to making an informed choice of package.
The Surrey CAQDAS project provides a good overview of packages and choices at https://www.surrey.ac.uk/computer-assisted-qualitative-data-analysis/resources/choosing-appropriate-caqdas-package
For resources the excellent books by Christina Silver and Nick Woolfe cover the three leading packages: NVivo, ATLAS.ti and MaxQDA.
Getting clear information of which packages are leading and their relative use is very difficult – however this paper provides some circumstantial evidence for their use in academic research:
Woods, M., Paulus, T., Atkins, D. P., & Macklin, R. (2016). Advancing Qualitative Research Using Qualitative Data Analysis Software (QDAS)? Reviewing Potential Versus Practice in Published Studies using ATLAS.ti and NVivo, 1994–2013. Social Science Computer Review, 34(5), 597–617. https://doi.org/10.1177/0894439315596311
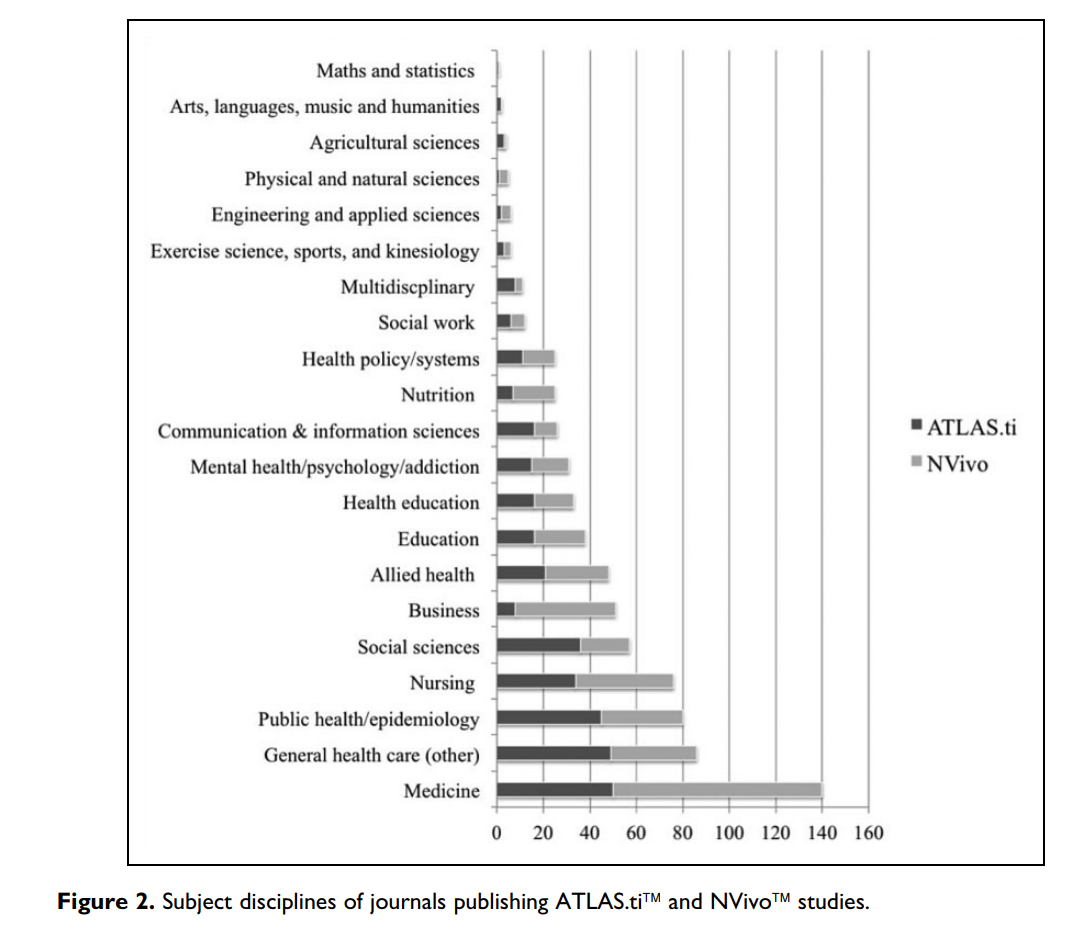
It reviews at patterns of publication citing the use of ATLAS.ti or NVivo (which were selected ” because they are two of the longest used QDAS tools (Muhr, 1991; Richards &
Richards, 1991). They are also the programs that we ourselves our familiar with; without this familiarity of our analysis would not have been possible (p599) and includes the following graph:
Another key consideration should NOW be if software adopted locks you in or enables project sharing and exporting via the recently published REFI standard – see Christina Silver’s excellent blog post in why this matters and why it should inform decisions of packages, especially for R-to-L scripts.
Suggested alternatives:
COMPREHENSIVE FULL-FEATURED CAQDAS PACKAGE SIMILAR IN SCOPE AND APPROACH TO NVIVO BUT WORKING WITH RIGHT-TO-LEFT TEXT:
My top recommendation: ATLAS.ti
Why? It supports REFI format for project exchange so you are not locked in.
Quotation approach for identifying data segments then attaching codes, linking to toher data segments and linking memos provides unrivalled support for multi-lingual work for example coding one script and then linking to translated sections in another (uncoded) script, or attaching a translation to a data segment via quotation comment.
Alternative Recommendation: MaxQDA
Another full-featured package with extensive support for mixed-methods and an excellent interface. The lack of support for REFI standard risks being locked in and unable to exchange or archive in a standard format – hence recommending ATLAS.ti instead.
MIXED METHODS FOCUS, COLLABORATIVE, CLOUD REQUIRED/DESIRED
Consider DeDoose for a mixed-methods focussed, collaborative package. However, in some settings an online collaborative cloud-based tool may not be appropriate so serious consideration needs to be given to the implications of that approach.
LARGE SCALE ANALYSIS AND TEXT MINING (i.e. functions promoted as part of NVivo Plus)
Consider QDA Miner with or without WordStat for support of all text together with advanced text mining capabilities.
Alternatively DiscoverText plays nicely in this space with some very clever features. (However it doesn’t support REFI)
SIMPLER FEATURES SOUGHT, PARTICIPATORY ANALYSIS METHODS, SOMETHING DIFFERENT
If you want to work with something visual, simple and just for text then Quirkos is fantastic and support R-to-L scripts.
And finally…
Comments welcome and updates will follow here if/when NVivo changes or other packages adopt REFI standard for example.

Use QDA MIner. It works very well.
LikeLike
Hi Tony,
It’s recommended in the alternatives. However as QDA miner is very different from NVivo it is perhaps better attuned to a move variables driven/data mining and mixed-methods based approach? I love the product and see it as having a very special place in the CAQDAS tapestry but equally find it less visual and (as much as I hate the term) intuitive than NVivo, ATLAS or MaxQDA
LikeLike
I had a similar rude awakening when I started to use Arabic in NVivo. Even though all my transcripts were translated to English, we had field notes and reports that were in Arabic and it was a very frustrating process to include them. Ended up using Atlas.ti which works well with Arabic. However, I truly miss the friendly use interface of NVivo
LikeLike
Wow – this is so useful! Thanks for sharing all your insights and saving me the frustration. It’s very hard finding any info on this. I’m not sure if any transcription and qualitative analysis software can cope with Libyan Arabic but that’s a different story … ATLAS.ti it is.
LikeLiked by 1 person